
ChatGPT Operator让过去企业数据安全的努力付之一炬
不难想象,这是相对于普通专用浏览器的下一步进化。专业浏览器获取数据,依然要解决很多工程化的问题,如数据定位、翻页、数据清洗,以及大量的特定平台适配工作,如 HTTP Response 解析或者 HTML DOM 解析。而 AI Agent 的整合,就是去工程化成本的历史性跨越,它可以完全消灭 RPA 的流程配置,以及专用浏览器的打造门槛。
ChatGPT Operator 的发布不可谓是几家欢喜几家愁:
做 RPA 的感受到了窒息
用 RPA 的感到了欣喜若狂
搞黑灰产的嗅到了新的商机
企业数据安全堡垒到了崩溃边缘
研发 RBI 的想借机宣传一波(Operator 内置了 RBI)
用 VDI 做数据不落地的失去了意义
大家可能会问,有这么夸张吗,看起来 Operator 还在早期阶段,未来能做成什么样还不一定,也不至于影响这么多行业。现实情况是,当有人证明了一个未经探索的方向的可能性后,这个方向就会开始快速发展,并衍生出一个繁荣的生态,这个世界并不需要一个无所不能的英雄,需要的只是能够指引方向的先行者 。
这篇文章就带大家粗浅的看看类似 Operator 这样的 AI Agent 给企业数据安全带来的实际影响,过去我们往往讨论和看到的是关于模型投毒、Prompt 劫持等关于大模型本身安全的担忧,实际上将模型用于数据的违法获取已经非常成熟,传统的数据安全堡垒早就形同虚设。
01 电商行业数据爬取的发展历程
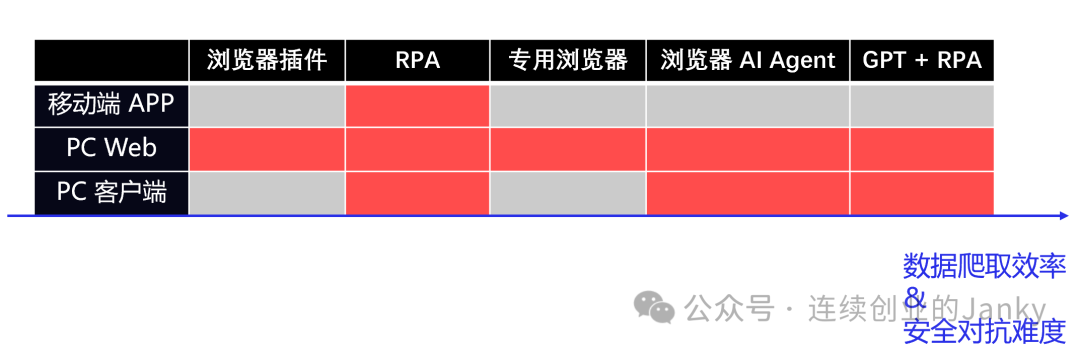
电商行业有着丰富且历史悠久的爬取数据应用场景,爬取数据者几乎包含所有行业从业者,从给商家提供各类服务的服务商,到商家自身,都是数据的极度渴求者,亦是永不停歇的实践者。因此本行业一直在与时俱进地迭代获取数据的最先进方式,大致的数据工具发展历程如上图所示。当然了对于那些极度违法的爬虫和利用平台接口漏洞获取数据的方式,这里闭口不谈,本文仅谈及“普通且基本合规的”数据获取方法,这些方法同样适用于获取任何企业内部系统数据的场景。
一、浏览器插件
曾经一度针对电商平台的浏览器插件非常流行,有针对 B 端客户端的各种“xx工具箱”用于爬取店铺或者类似淘宝生意参谋数据平台的数据,也有针对 C 端用户的各种“比价插件”。现在这些插件几乎消失殆尽,消亡的原因来自于各大电商平台的打击。技术上,电商平台可以检测这些插件的存在,然后实施相应的屏蔽;法律上,电商公司可以起诉这些插件的开发者;生态上,电商平台还会处罚使用这些插件的商家。综合治理之下,这些插件就慢慢消失或者迭代到下一阶段去了。
电商数据插件的兴起,是做爬虫之后,是相比爬虫更正规且稳定的数据获取方式。且最为重要的是,数据获取的行为隐藏在正规的办公需求之下,这些插件还会提供更多的办公功能给到用户,且最终的数据获取行为被转移到了商家自身,而不是插件默认的行为,以此来洗白爬数据的名声。
再者,浏览器插件能获取到非常多的数据,看看 ChatGPT 插件需要的运行权限就可知一二。试想一下,当公司员工为自己浏览器安装了这些插件之后,那么逻辑上通过浏览器访问公司的内部系统,客户管理的、财务的、OA 的、知识库的,所有这些数据也就非常自然的出去了。在获得 GPT 智能体验的时候,企业数据安全荡然无存。
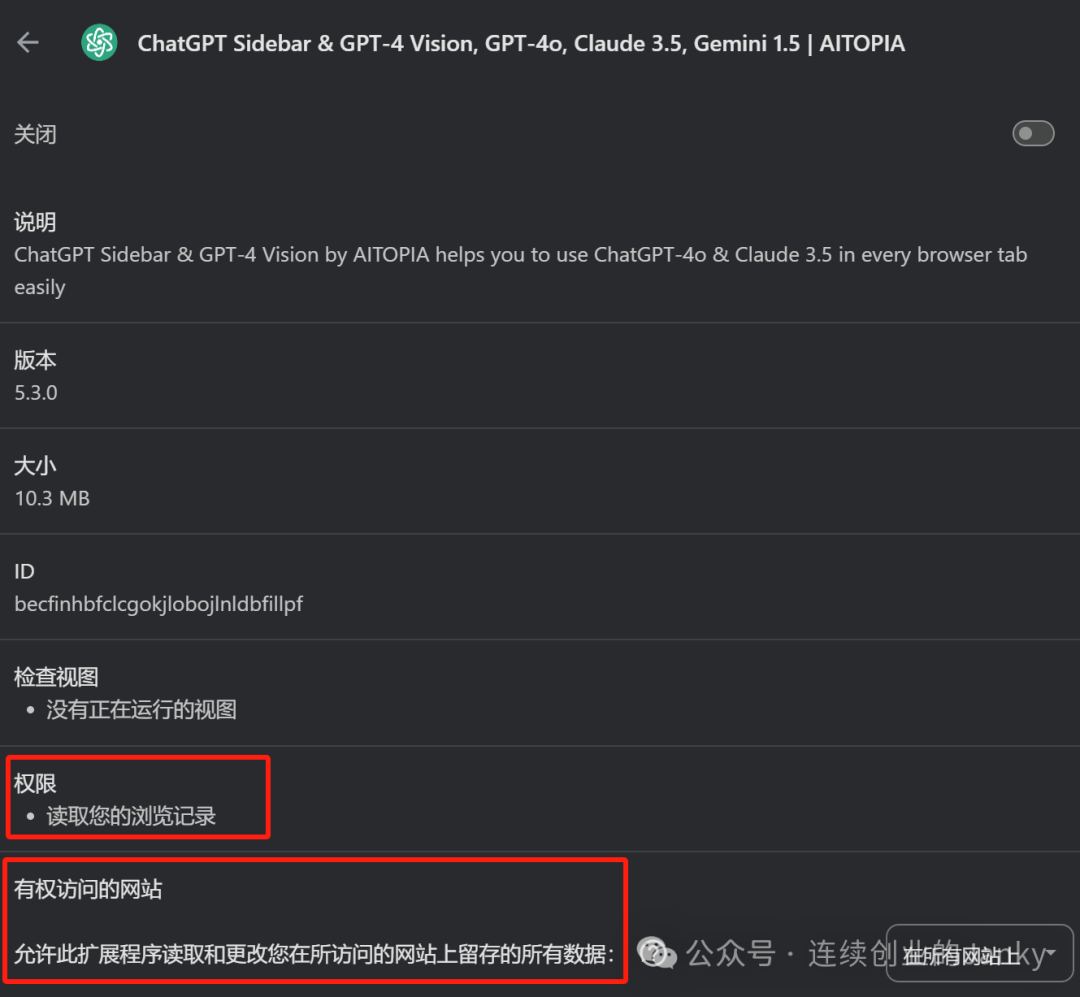
二、RPA
浏览器插件固然好用,但对抗平台的检查落入了下方。平台(网站)可以尝试检查浏览器安装了哪些插件,或者去查看自己页面里是否被注入了外来的 JavaScript 代码来查看插件的存在,从而实施针对插件的风控规则。如下面这种最为原始的检查方法,虽然 Flash 已经停止支持,这里仅作为示例:
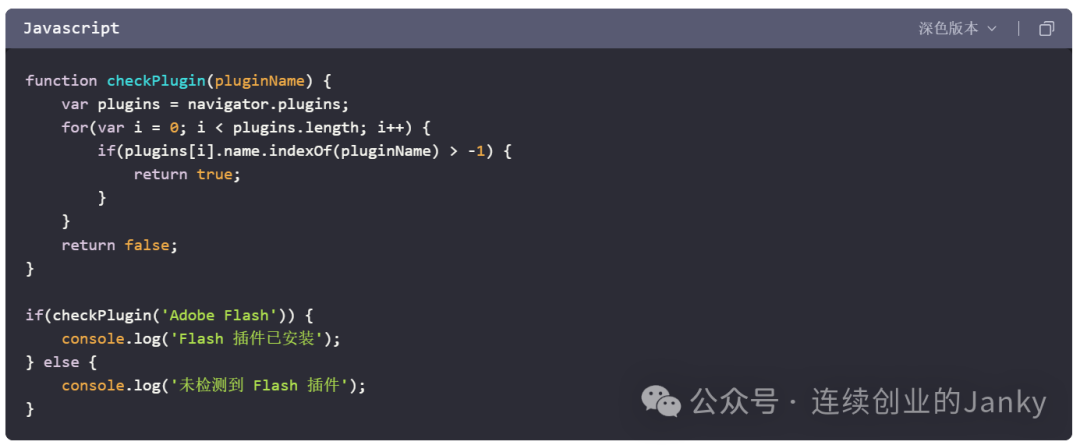
因此插件逐渐退出历史舞台,继而 RPA 开始登场。RPA 俗称“模拟人工操作,进行办公自动化”,如果对 RPA 不了解的读者,还请自行去科普,这里不浪费篇幅展开介绍。
RPA 用在数据爬取的场景,相比于浏览器插件,主要是做两个方面的优势:
因为是模拟人工操作,对于平台来讲,很难识别到是机器行为。
RPA 60% 用于正常的办公场景,帮助企业和员工自动化重复性的办公操作,40%(作者主观臆断)用于数据爬取,平台很难直接完全封禁 RPA ,这无法对平台自身的用户交代。且电商平台通常还在推广自身的 RPA 产品。
三、专用浏览器
RPA 也有自身的缺陷:
自动化流程配置复杂,使用者需要具备一定的 IT 技术技能。
动态交互较多的 Web 页面,难以圈选到需要爬取的数据字段。
平台布局更新,RPA 流程需要更新。
平台的风控,如弹窗、验证码;电脑系统内的其他弹窗,如“是兄弟就砍我一刀”这样的游戏弹窗,会打断 RPA 流程。
因此行业内发明出了,专用浏览器,这是相对于原来的浏览器插件和 RPA,进一步开启了上帝视角,可以规避页面 UI 的不确定性和插件容易被风控的弱点。尤其在一些抢对抗的场景,如竞对之前的情报和数据获取,应用得风生水起。
四、浏览器 AI Agent
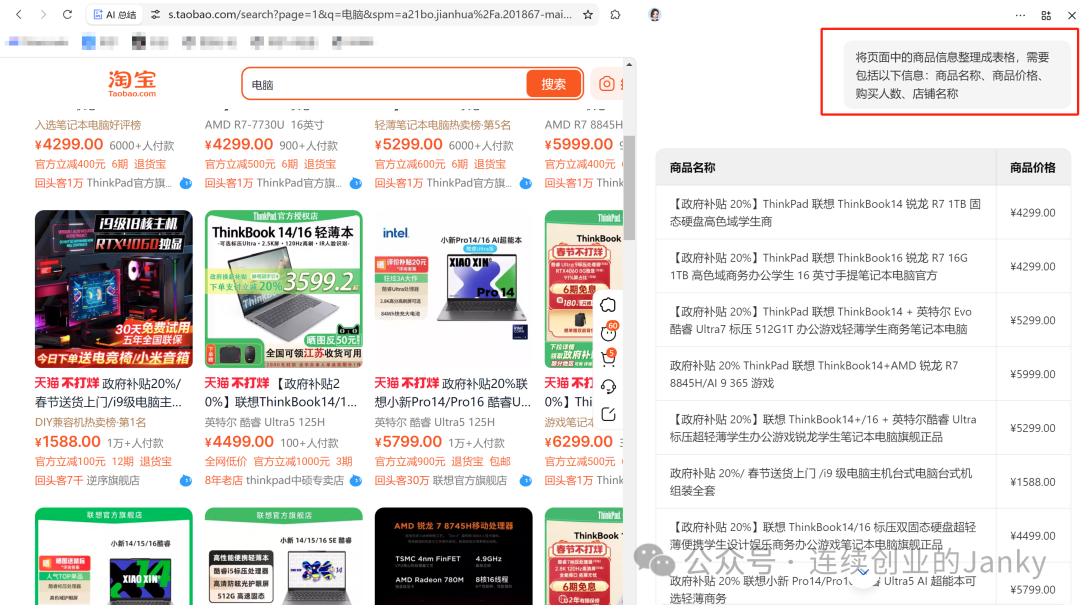
不难想象,这是相对于普通专用浏览器的下一步进化。专业浏览器获取数据,依然要解决很多工程化的问题,如数据定位、翻页、数据清洗,以及大量的特定平台适配工作,如 HTTP Response 解析或者 HTML DOM 解析。而 AI Agent 的整合,就是去工程化成本的历史性跨越。如下面这样的效果,完全消灭了 RPA 的流程配置,以及专用浏览器的打造门槛。
五、浏览器 AI Agent+ RPA
这正是 ChatGPT Operator 的本质面貌。Operator 并不是其宣传的世界第一家干这事的产品,在这之前已经有了 DoBrowser 以及开源的 Browser Use。他们想要做的是打通整个自动化的链路,把数据的获取、数据分析、和动作执行完全打通。GPT 模型发挥作用的部分,仅仅是数据分析阶段,其他两部分都极度依赖工程化的技术。因此,我本身并不惊讶和赞叹 OpenAI 此次 Operator 发布的 AI 高度,那已经是他们开始在脱离模型,转而进入工程化组装阶段。且,他们也不是第一个这么干的了,下面是提早 Operator 2 个月发布的 DoBrowser。
可以预判未来会有很多这样的产品,极其快速的推出市场,试想一下,我们把这样的工具用在企业内部,企业要如何保护自身的数据资产安全?
靠 DLP?
靠 VDI?
靠桌管?
靠防火墙?
02 应对之策
以彼之道还施彼身,应对 浏览器 AI Agent 对于数据安全带来的风险,只能以浏览器以还之,敬请期待下一篇《因为 GPT,浏览器安全,正在变得前所未有的重要》。
本文转自https://www.secrss.com/articles/75151

- 国家金监总局发布《金融机构合规管理办法》
93 浏览金融

81 浏览AI
81 浏览安全资讯
- 国家发改委等六部门印发《关于促进数据产业高质量发展的指导意见》
79 浏览政策

77 浏览卫生医疗
文章评论